Three days ago I came across an interesting post on Hacker News <here> discussing the Sherlock Project <here>. This project is a little over 6 years old and is still getting updates by the community. Likewise, this and similar projects (i.e Maigret) still make rounds online when they are posted. Because of that, I thought it’d be a worthwhile post to share and some thoughts on the project. I’ll continue this effort by posting follow up posts for similar projects and my respective thoughts.
TL;DR — The Sherlock Project provides a great starting point for your OSINT endeavors and is simple to use. However, there are a lot of limitations (speed, accuracy, inconsistent results, lack of integrations, and support of advanced use cases) that prevent this from being a more complete solution. It had a 23.5% success rate for finding accounts actually owned by me and a 67.6% success rate for identifying websites where my username was registered already.
Installing and Usage
Installation was very easy using a fresh Rocky Linux VM
sudo yum install python
sudo dnf install python3-pip
pip install pipx
pipx install sherlock-project
sherlock --version
Done----------------------
Viola!
[vcommand@vulncommand sherlock]$ sherlock --version
Sherlock v0.15.0
My initial run took approximately ~38 minutes to execute for 34 results.
27/12/24 00:04:48 sherlock <<replace with my username>>
27/12/24 00:42:45 historyA side tangent, I highly recommend adding timestamps to your history command in your Linux environment. It’s a relatively easy modification of your ~/.bashrc configuration steps can be found <here>. This is not a perfect way of measuring performance or time of execution, but it’s a quick and easy way of understanding roughly when you executed something as well as how long it took.
At first glance, the results were cool to see — lots of true positives where it found my username from the listed website that I definitely use. Sadly, there were a lot of sites I definitely didn’t have accounts for — and some that were legitimate accounts, but not accounts associated with me (somewhat common username). With that being said below is an example output
[vcommand@vulncommand sherlock]$ sherlock myuser
[*] Checking username myuser on:
[+] 3dnews: http://forum.3dnews.ru/member.php?username=myuser
[+] DeviantART: https://myuser.deviantart.com
[+] Discord: https://discord.com
[+] Duolingo: https://www.duolingo.com/profile/myuser
[+] Fiverr: https://www.fiverr.com/myuser
[+] Freesound: https://freesound.org/people/myuser
[+] GitHub: https://www.github.com/myuser
[+] Gravatar: http://en.gravatar.com/myuser
[+] HackenProof (Hackers): https://hackenproof.com/hackers/myuser
[+] HackerRank: https://hackerrank.com/myuser
[+] Instagram: https://instagram.com/myuser
[+] Lichess: https://lichess.org/@/myuser
[+] Naver: https://blog.naver.com/myuser
[+] Newgrounds: https://myuser.newgrounds.com
[+] ProductHunt: https://www.producthunt.com/@myuser
[+] PyPi: https://pypi.org/user/myuser
[+] Reddit: https://www.reddit.com/user/myuser
[+] Roblox: https://www.roblox.com/user.aspx?username=myuser
[+] Scratch: https://scratch.mit.edu/users/myuser
[+] Scribd: https://www.scribd.com/myuser
[+] Shpock: https://www.shpock.com/shop/myuser
[+] SlideShare: https://slideshare.net/myuser
[+] Smule: https://www.smule.com/myuser
[+] Snapchat: https://www.snapchat.com/add/myuser
[+] Strava: https://www.strava.com/athletes/myuser
[+] TLDR Legal: https://tldrlegal.com/users/myuser
[+] Telegram: https://t.me/myuser
[+] Trello: https://trello.com/myuser
[+] Twitch: https://www.twitch.tv/myuser
[+] Wattpad: https://www.wattpad.com/user/myuser
[+] Xbox Gamertag: https://xboxgamertag.com/search/myuser
[+] YouTube: https://www.youtube.com/@myuser
[+] babyRU: https://www.baby.ru/u/myuser
[+] mercadolivre: https://www.mercadolivre.com.br/perfil/myuser
[*] Search completed with 34 results
False Positives (not a real account)
When reviewing the list, I visited some of the URLs it presented to test if the accounts were indeed valid. Upon closer inspection, a few of them seemed suspicious of being valid, especially the .ru sites. When visiting them, I noticed that the accounts definitely did not exist. This is when I did a deep dive into how it is collecting the information.
1> Sherlock Project has a list of sites that were removed due to false positives found here
The above document outlines a list of ~124 (counting </h2> tags in the .md source) sites where the project removed the results due to false positives (some cases all users returned a valid response code). Because of this, I suspect the maintenance and upkeep for this project is relatively high…and my suspicions were correct leading to #2.
2> Moved or Dead websites still in the list
Below is an example where the service checks a URL that no longer works but is still included in the search. This URL may be active and just down at the time of my search but there are more than just this example from my analysis.
+++++++++++++++++++++
TARGET NAME : skyrock
USERNAME : myuser
TARGET URL : https://myuser.skyrock.com/
TEST METHOD : status_code
Results...
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Unknown
+++++++++++++++++++++3> Completely Wrong Results (No account actually found)
I was hoping that this would never actually be the case, but it turns out that some websites say there is already an account found, but when inspecting further, there isn’t an account. As an example, https://slideshare.net was listed as a True Positive, but upon checking it says the username is available (edited the HTML to replace my actual username on the page 🙂 )
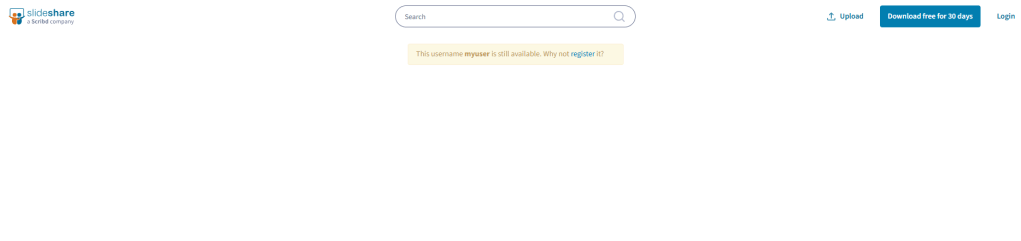
From the looks of it, Strava and a few others should be on the list of full blown false positives. Running this multiple times yields different results as well. For example, my first run of this tool found an account on myspace, the second run, did not.
Benign Positives (valid account not owned by me)
I don’t have much to say on this use case since there are certainly username overlaps on the internet. Some of the findings had recent real activity showing that I am not the only one with this username anymore. This username has existed since ~2005 for me and is pretty unique and using an English word with a sequence of numbers. I suspect a leak of username and passwords may ended up in the hands of some of these sites and they imported the users to their backend. That’s a complete reach of a conclusion and entirely speculative. When I used to walk ethical lines, I know I definitely did exactly that — acquire user information and import it into my user database to bump up the number of registered users. Either way, I would say use caution when reviewing the results and use skepticism before assuming a result is valid.
True Positives (accounts owned by me)
Of the 34 total hits I went and visited each one to validate if the findings were real. I must say this mostly felt like a personal Internet Archive where I rediscovered accounts on websites that were long lost.
Summary of the Analysis
In total, 23.5% (8/ 34) of the findings were actually owned by me. So this was helpful for me to dig up old accounts that I forgot existed. However, 32.3% (11 / 34) of the accounts were false positives and the account didn’t actually exist or the website did not handle the username despite the username being successfully detected. The remaining 44.1% (15 / 34) of sites where my username was detected were actual valid usernames, however, they were not owned by me. This isn’t meant to be an insult to the creators and maintainers and it certainly is not meant to be overly dramatic to try and sway you from using the Sherlock Project. This is simply a one off analysis of a cool project to help users understand the tool a bit more deeply.
Parsing the Results
I was excited that based on the documentation, that there would be some useful output by default in the username.txt in the directory I executed the command from.
[vcommand@vulncommand sherlock]$ ls -ls
total 4
4 -rw-r--r--. 1 vcommand vcommand 1275 Dec 27 00:42 myuser.txt
Unfortunately, this txt file is just the command line output from above, nothing additional is stored. I was hoping for some HTTP responses or something a bit more deep to use. Not to worry, I’m sure there’s something in –help. From the looks of it, there is a –verbose (-v, -d, or –debug) mode which will display extra debugging information and metrics and a –dump-response setting which will bump the HTTP response to stdout, nice! Let’s run the tool again with these settings.
My first run, I saw a lot of useful information, including response codes and HTML! However, there are two draw backs on this. The first, is that the HTML is only shown if there is a non 200 response code. Meaning, I will only see the contents of a page if it errors out. This helps debugging where the project goes wrong but it doesn’t help with validating results to make sure the websites where your account is found is actually a valid result (see False Positives above). The second problem, is that the output does not save the Verbose output to the myuser.txt! This hurt since the project takes upwards of 30 minutes to run. On my third execution of this project I ran it with the following command to capture the verbose and debug output:
[vcommand@vulncommand sherlock]$ sherlock -v --dump-response myuser > myuser-verbose.txt
With the engine fired up I now had an output to review with you all.
Example #1 – 404 Output
The below is an example output of a 404 without an error where the account is not identified.
+++++++++++++++++++++
TARGET NAME : 2Dimensions
USERNAME : myuser
TARGET URL : https://2Dimensions.com/a/myuser
TEST METHOD : status_code
Results...
RESPONSE CODE : 404
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Available
+++++++++++++++++++++
Example #2 – Response with Error but 200 Status Code
The below is an example of the tool output ting some debug information — this being a weird case since the Response Code is 200, but the output identifies that the response is actually a 404 and has an error.
+++++++++++++++++++++
TARGET NAME : 1337x
USERNAME : myuser
TARGET URL : https://www.1337x.to/user/myuser/
TEST METHOD : message
Results...
RESPONSE CODE : 200
ERROR TEXT : ['<title>Error something went wrong.</title>', '<head><title>404 Not Found</title></head>']
>>>>> BEGIN RESPONSE TEXT
<!DOCTYPE html>^M
<html>^M
<head>^M
<meta charset = "utf-8">^M
<meta http-equiv = "X-UA-Compatible" content = "IE=edge">^M
<title>Error something went wrong.</title>^M
<meta name = "viewport" content = "width=device-width, initial-scale=1">^M
Example #3 – Account Found (False Positive)
The below renders a 200 Response code, however, when translating the Russian it actually says “The user is not registered and does not have a profile to view.” So even though the verdict says Claimed, this is a False Positive.
+++++++++++++++++++++
TARGET NAME : 3dnews
USERNAME : myuser
TARGET URL : http://forum.3dnews.ru/member.php?username=myuser
TEST METHOD : message
Results...
RESPONSE CODE : 200
ERROR TEXT : Пользователь не зарегистрирован и не имеет профиля для просмотра.
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Claimed
+++++++++++++++++++++Example #4 – Forbidden (Verdict Available)
The response code is 403, which may be the expected output for this site when a username is available. However, when I visit my account in the browser it returns a 404, weird. This tells me that the tool does not handle 403 properly, especially considering it does not output the HTML despite a non-200 response code. However, the verdict is correct!
+++++++++++++++++++++
TARGET NAME : ArtStation
USERNAME : myuser
TARGET URL : https://www.artstation.com/myuser
TEST METHOD : status_code
Results...
RESPONSE CODE : 403
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Available
+++++++++++++++++++++
Example #5 – Bad Gateway Response Code 502 (Verdict: Available)
Another case where a bad response code has no HTML output and yields a verdict of available despite an error code that could indicate otherwise (I get a 404 when I visit the page myself). However, the tool is right in this case, there is no user with this username.
+++++++++++++++++++++
TARGET NAME : Choice Community
USERNAME : myuser
TARGET URL : https://choice.community/u/myuser/summary
TEST METHOD : status_code
Results...
RESPONSE CODE : 502
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Available
Example #6 – Account not Found Response Code: 400
Here is an example where the status code was 400 and the username was available!
+++++++++++++++++++++
TARGET NAME : Clapper
USERNAME : myuser
TARGET URL : https://clapperapp.com/myuser
TEST METHOD : status_code
Results...
RESPONSE CODE : 400
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Available
+++++++++++++++++++++Example #7 – Valid Response Code of 200, True Positive (Verdict Claimed)
The below is an example of when the tool is 100% spot on. It identified that my username was already claimed on the site, it had a successful HTTP response code, and it was actually correct upon further review. Again, the sad thing is that this does not output the HTML response here. I would love to automate triaging the output to determine if there are false positives or monitor for changes.
+++++++++++++++++++++
TARGET NAME : Lichess
USERNAME : myuser
TARGET URL : https://lichess.org/@/myuser
TEST METHOD : status_code
Results...
RESPONSE CODE : 200
>>>>> BEGIN RESPONSE TEXT
<<<<< END RESPONSE TEXT
VERDICT : Claimed
+++++++++++++++++++++
[+] [608766ms] Lichess: https://lichess.org/@/myuser
Conclusion
All in all, this was a fun exercise and deep dive into this project. I learned a lot, had some nostalgia while doing so. There are lots of opportunities to improve this project even further, who knows, I might even attempt to make some of these changes myself! For now, I hope you enjoyed this post and learned something yourself!

Leave a comment